For keystroke-logging the writing sessions in our experiment, we use Inputlog. It's developed at the University of Antwerp and free to use for everybody. On the Inputlog website you also find information on how to use it and on how it has been used in other studies.
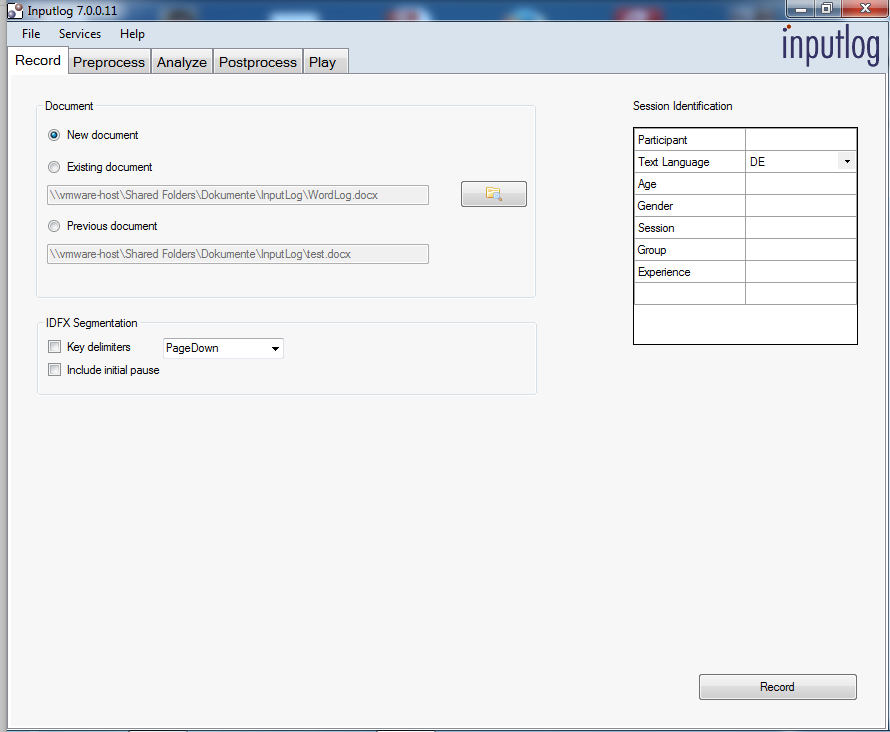
In the record tab, you enter the information on the participant and the writing session and press "Record". MS Word opens automatically with a fresh new document. The Inputlog window goes to the background and doesn't disturb your writing. When you finish your writing, you bring the Inputlog window back to the front, press the "Stop recording" button and you're done. Inputlog switches to the Analyze tab and lets you select analyzing scripts which you can also modify.
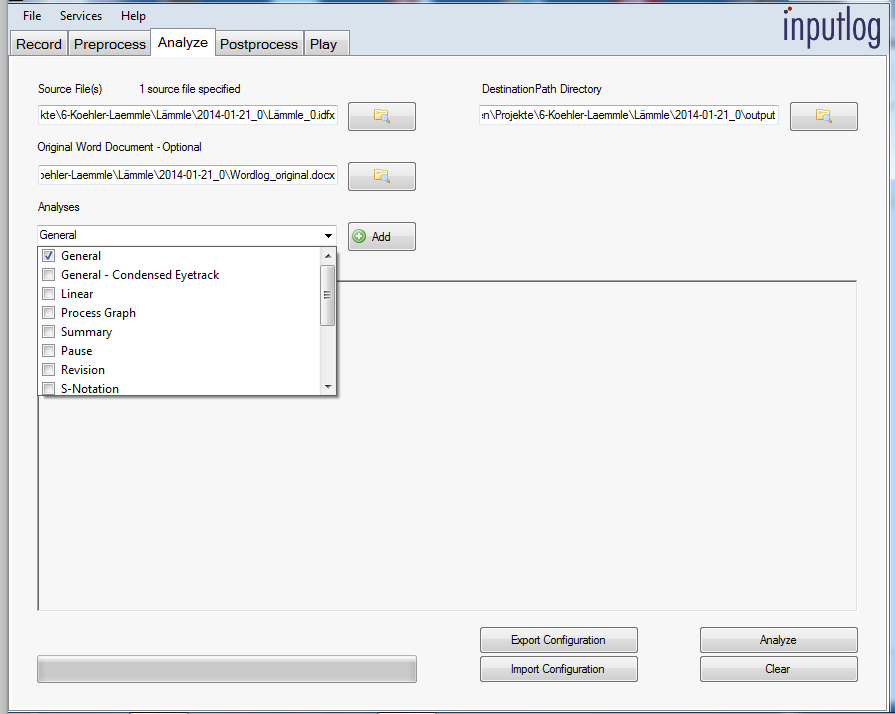
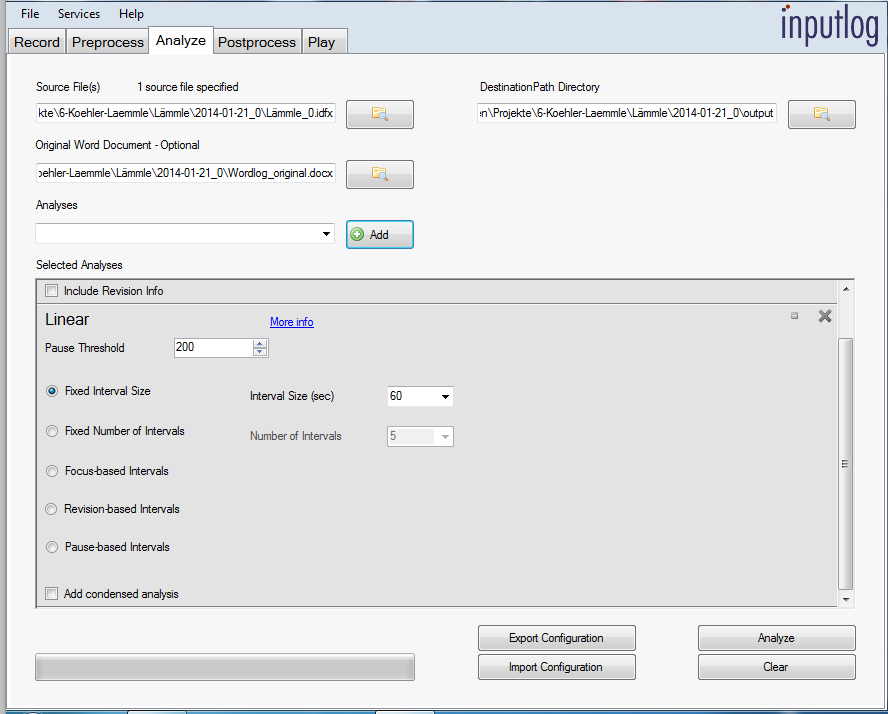
Of course, you could run your own scripts on the recorded file. All keystrokes are stored in an idfx file, which is an XML file containing the participants information as meta data and all information on keys pressed and mouse movements as events. You could load it into an XML Database like BaseX and run XQuery scripts.
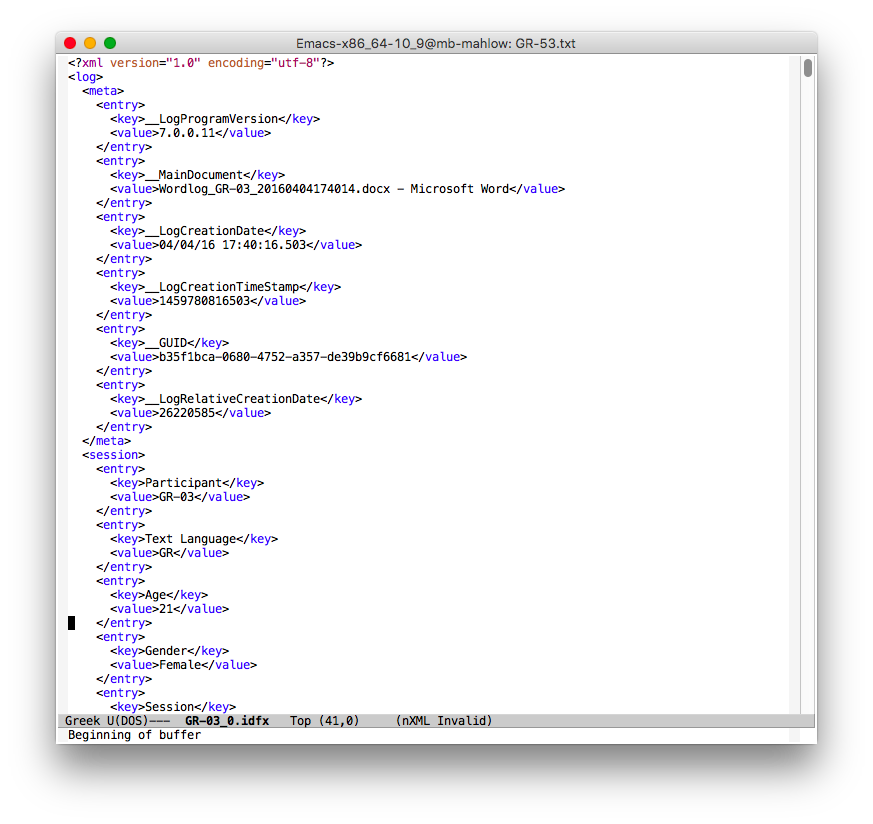
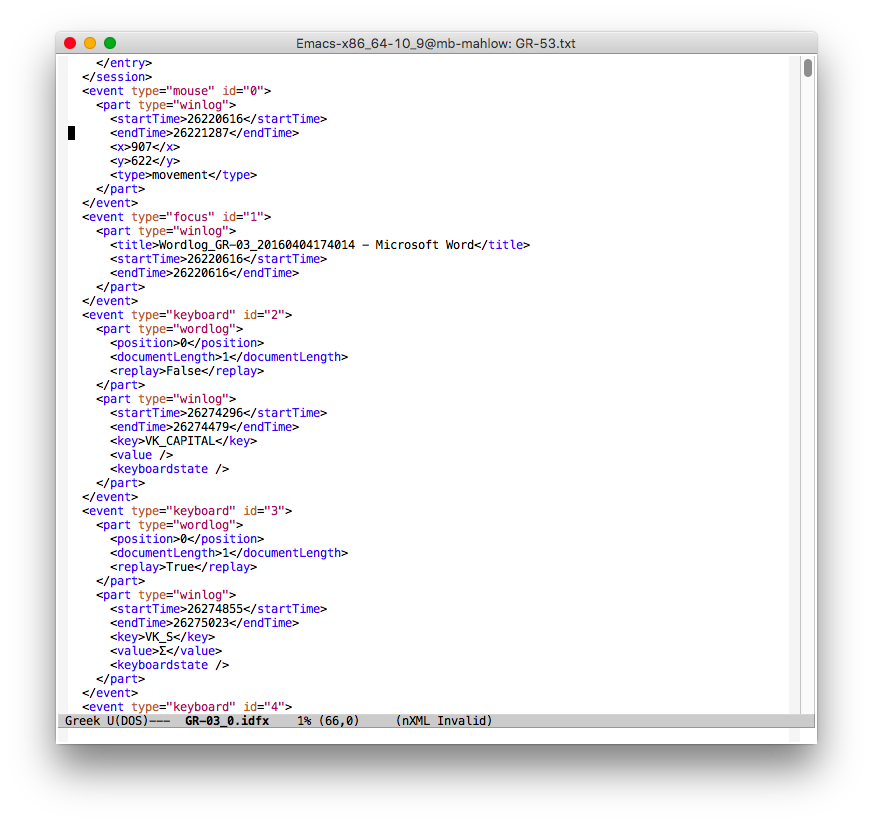
So, everything looks as ready for processing. But it's better to look more closely at your data first. The main issue when dealing with non-English language data is always encoding. The snippet shown above actually has Greek letters and it is encoded in UTF-8 (Emacs makes this information explicit at the bottom). Students wrote texts in Greek, all final texts also show Greek letters. So everything should be fine, shouldn't it?
Actually, the information in the idfx file is not taken from MS Word, but directly from the keyboard. So no matter what your setting in MS Word is, the setting for the keyboard in Windows is relevant. And we discovered that for some sessions, this was set to English and not to Greek. Which means that the information in the idfx file are actually ASCII keys pressed -- because of the setting in MS Word, this information is converted into the corresponding Greek characters and the characters in MS Word appear as Greek characters.
The question is: Does this affect the analysis? We could simply replace the English letter with the corresponding Greek letter. There are conversion tables available and even the keyboards are labeled accordingly, so this should be easy. But then, Greek has accented vowels which are not characters of its own, but are constructed similar as you would write them by hand: You put an accent on the vowel. Which means you press the key for the tonos (the key right to P (which would be the "ü" on a German keyboard and the ";" on a US-English keyboard)) and then the vowel. The result is a vowel with tonos, one character only although we pressed two keys. And that's how it is recorded when the keyboard is set to Greek.
However, if the keyboard is still set to English, Inputlog records that two keys have been pressed, the key for the tonos is not treated as a dead key. The following image shows two idfx files
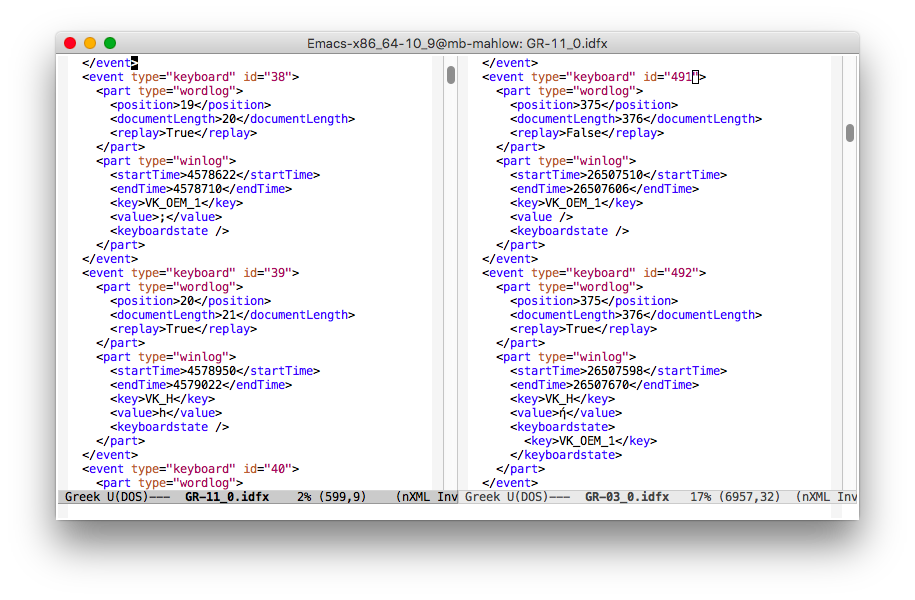
In both cases, we produce the same character, the small letter eta with tonos: ή. In the right file (GR-03_0.idfx), the key for the tonos is pressed (VK_OEM_1) at position 375 as the 491st event. Then the key VK_H for the small eta is pressed as the 492nd event, but we are still at position 375. The tonos key is actually treated as dead key (there is no key value) and after pressing the eta key η, the value is "ή". But if we look at the left file (GR-11_0.idfx), we find the production of ή to be recorded differently: the key for the tonos is pressed as event 38 at position 19 and there actually is a value: ";". Then the key VK_H is pressed as event 39 at position 20 and the value is "h". So the tonos is not treated as a dead key, but as any other key with an actual value. In the idfx file, no accented value is visible, we cannot simply replace ASCII values with the corresponding UTF-8 characters. A more sophisticated recoding would be needed.
Let's see what this means for our analyses in a later post.